
Word clouds are popping up everywhere at the moment. It's no surprise as they are an intuitive way of quickly grasping the major themes of a body of text. They have real application in the business world, and are widely used as a tool in business intelligence and market research.
Below is an example of a word cloud I generated of the recent Nvidia COMPUTEX 2023 keynote given by Nvidia CEO Jensen Huang. The cloud was generated in Python and clearly underlines the importance of AI to Nvidia's core business selling GPUs.

In this article we'll discuss a number of common use cases for word clouds, show how they can be applied to compare two competitors, and finish off by showing how you can create your own word cloud in Python.
Growing in Popularity
Word clouds provide an easy to digest and intuitive visual representation of large bodies of text. The size and prominence of the words in the cloud correspond to their importance or frequency in the text. When applied to specific text, a word cloud allows one to quickly grasp the key themes and focus areas being discussed.
A Google trend analysis confirms the popularity of Word Clouds is sky high. They are no longer confined to the domain of personal blogs as tag clouds, but have found real use in the business wold. This is unsurprising due to the rapid growth of the data analytics industry, and the fact that they can deliver meaningful insight when correctly used.

A word cloud works by collating the frequency of words in a body of text and displaying the results as a weighted list. Words that are used more frequently are assigned a higher prominence in the resulting image and are usually plotted in brighter colors and a larger font size. This provides an intuitive means to quickly highlight the major themes of the text.
Typical Use Cases
Words clouds are a popular way to visualise the themes around political speeches, company keynote addresses, company results presentations and IPO filings.
There usefulness don't stop there and some other common applications include:
- Brand analysis to assess brand perception.
- Content optimization through keyword identification as part of an SEO strategy.
- Initial data exploration of large datasets to identify overarching themes.
- Market research through the visualisation of customer feedback, survey responses and product reviews.
They can of course be applied anytime a large body of text has been generated or collated.
Why Use Word Clouds
Word clouds are generally not used in isolation and should be thought of as one tool in your data analytics toolbox. They are a very effective way to communicate key messages, trends and themes in a dataset. I personally like to use a word cloud in conjunction with a table or bar chart of the most repeated words, as I think there is real benefit to seeing the actual frequency distribution as well as the image.
Here are four areas where a word cloud can be effectively used to provide otherwise hard to obtain insight into a company or industry.
Identification of Key Messaging and Priorities
Core themes and company messaging reveals itself through the frequency and prominence of words used. When applied to keynote addresses or forward looking statements one can quickly get a feel for the company's priorities and strategy.
Analysing Communication Effectiveness
It is imperitive that a company is able to effectively communicate its strategy to stakeholders. Generally a company will pick a small number of strategic keywords and then try to clearly push those in all published communication. A word cloud helps to identify whether these keywords have been effectively communicated or not.
Companies take on certain personas to better articulate their value offering and to connect with their target market. One of the most famous examples of this is the iconic I'm a Mac I'm a PC adverts which positioned Mac as cool and creative vs the boring and analytical PC. Word clouds can analyse the language used to communicate this messaging before an ad campaign is run, to ascertain whether in fact the messaging is effectively communicated.
Trend Analysis
Aggregating a large dataset of text within an industry, and building a word cloud around that data is an effective means to study any macro trends and themes. A good example would be the current AI goldrush in the technology sector at the time of writing this article. Perhaps a year earlier the dominant theme would have been Blockchain and cryptocurrency?
Competitor Analysis
Analysing your company's messaging against that of your competitors allows you can quickly identify where strategies are converging and diverging. This can then inform your own strategic decision making, and help you to tailor your strategy in order to win market share away from your competitors.
Comparing Apple and Google's Recent Keynotes
Let's compare the latest Keynote addresses from Apple and Google through the creation of a word cloud and frequency table.
Apple's WWDC 2023 conference took place from the 6th to the 9th of June 2023 and was headlined by the unveiling of the Apple Vision Pro headset.
Google I/O 2023 took place on May 10th 2023 and was characterised (memed) by the (over)use of the terms "AI" and "generative AI".
Apple WWDC 2023
Apple's word cloud from the WWDC 2023 keynote address is shown below. Unsurprisingly the address was dominated by the launch of the apple Vision Pro headset. In addition, new Macs were unveiled, macOS 14 Sonoma debuted, as did iOS17, iPadOS17 and watchOS 10.

What is absent from the Apple word cloud is probably more revealing than what is present. There is not a single mention of the term "AI" or "Virtual Reality" even though the keynote was dominated by the launch of Vision Pro, a virtual reality headset and uses an enourmous amount of AI technology in the background. Apple are incredibly obsessive about their messaging and so the non-use of these terms was clearly deliberate.
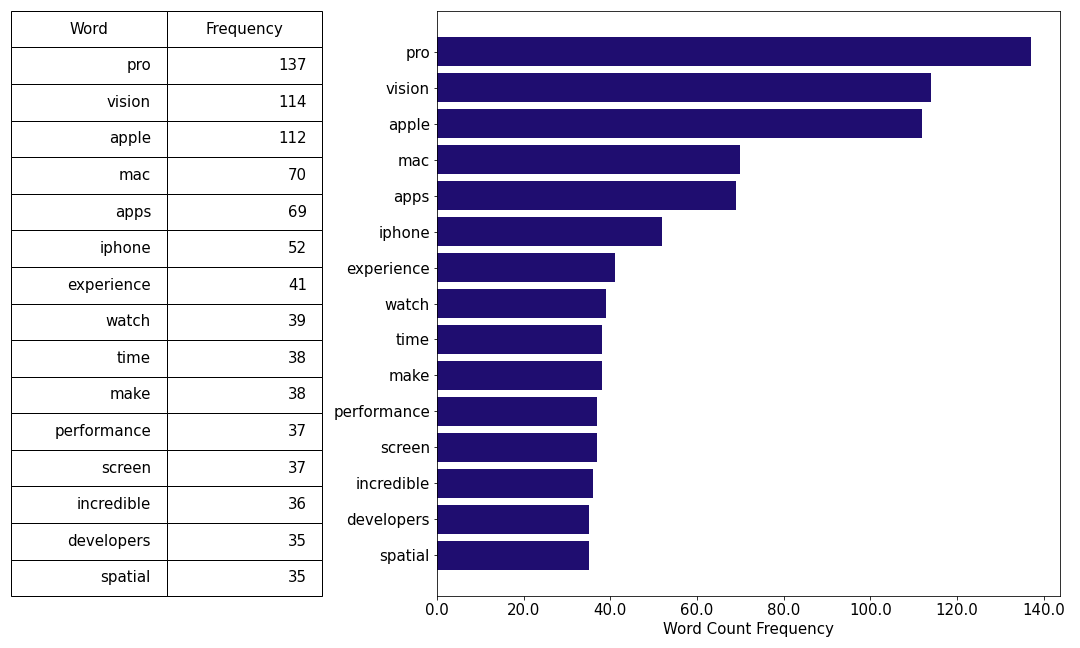
AI is in the midst of an enormous hype cycle at present (July 2023) and Apple clearly did not want to be associated with any negative sentiment that will surely come as the hype cycle tops up the peak of expectation and falls into a trough of disillusionment. They did however use the less charged term "machine-learning" eight times which is analogous to AI.
Apple also like to maintain exclusivity when it comes to naming the technology that that goes into their products. I suspect that this is why the Keynote did not use the term "virtual reality" but instead Apple introduced us to "Spatial Computing". Youtuber and Internet Personality MKBHD put together a great video discussing just this, and specifically Apple's desire to control the narrative around their technology as a means to avoid comparisons between their product offering and that of their competitors.
Google I/O 2023
Google's recent IO event was presented in May 2023. Major topics covered included generative AI, PaLM 2 Large Language Model, Google's chatbot Bard, and a set of new Pixel phones.
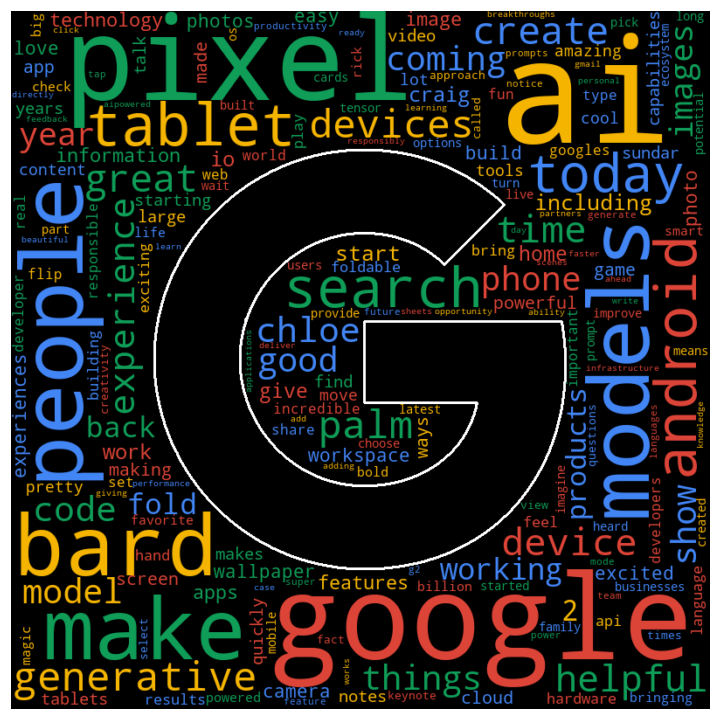
The term "AI" unsurprisingly dominates the keynote and was used a whopping 123 times. Google is clearly in an AI arms race with Microsoft (OpenAI), and after an embarrasing launch of Bard where the AI chatbot made a factual error, is pushing its AI technology very hard.
The clear overarching theme of the address is that Google sees the future of the company being inextricably linked to AI. Other AI related terms dominating the keynote include, "models", "Bard", "generative", and "create". Google's core product, "search" was only mentioned 35 times against AI's 123 mentions.

Build your own Word Cloud in Python
Let's now go through a simple example of how to build your own word cloud in Python. If you are interested in following along then download the example notebook and input text files from Github.
I'm using the word_cloud package to build my clouds. The package is available on pypi or through a pip install.
pip install wordcloud
The word_cloud package is easy to use and well documented. There is a lot of functionality built in which makes it very customizable, but we'll keep it relatively simple here.
Word Cloud Text and Stop Words
In order to build a word cloud you need a body to text to examine. Let's use the keynote address from Microsoft Build 2023. To get the transcript I just clicked on the Youtube link to the keynote and downloaded the transcript from there.
My approach is to open the text file and then convert the contents of the file to a single string that I can process and then feed into the word cloud.
def load_words_as_string(path_to_file):
with open(path_to_file, 'r', encoding="utf8") as f:
text = f.read()
text = text.replace('\n', ' ').replace('\r', '')
text = ' '.join(text.split())
return text
Once I have the string of text, I like to remove all the punctuation so that I don't end up with full-stops and the like in the cloud. A simple function using regular expressions takes care of that. I also convert everything to lower case so as not to run into issues with upper, title, and lower case words being counted separately.
import re
def cleanup(text):
text = text.lower()
clean_text = re.sub(r'[^\w\s]', '', text)
return clean_text
Stop Words
An important concept when building a word cloud is that of stop words. These are a set of the most common words in a language that are classed as unimportant in the sense that they do not add much value to understanding the gist of the text. Words like and, or, to, for, am are all good examples. We don't want these words filling our cloud so we remove them before hand.
The word_cloud package actually has a built in set of stop words that you can use, however, I prefer to make use of a more comprehensive list. There is a very comprehensive list that you can download from the IR Multilingual Resources at UniNE, a Swiss university. I load these words into a list and then clean them up in the same manner as the words cloud text in order to remain consistent.
def load_words_from_file(path_to_file):
# outputs the text as a list
sw_list = []
with open(path_to_file, 'r', encoding="utf8") as f:
[sw_list.append(word) for line in f for word in line.split()]
return sw_list
stopfile = 'englishST.txt'
stop_words = load_words_from_file(stopfile)
stop_words = [cleanup(word) for word in stop_words]
You may want to add a number of your own custom stop words to your list. This is usually performed on a case-by-case basis after generating the cloud and seeing many instances of a particular word that doesn't add much value. Since stop_words is simply a list, it is easy to append additional terms to that list as necessary.
Word Count Dict
I now have a string of cleaned up text and a list of stop words. The next step is to create a dictionary of all the words not included in the stop words list, and a count of the number of times each of those words appear. Each valid word is necessarily unique and so will form the dictionary keys, with a corresponding count of the frequency of each word in the text as that key's item.
This is accomplished using the built in Counter function. I first use Counter to build a dictionary of all words in the text, and then remove all those that appear in the list of stop words.
from collections import Counter
def createWordCount(text,stop_words):
word_counts = Counter(text.split())
word_counts = {word: count for word, count in word_counts.items()
if word not in stop_words}
return word_counts
The final word count dictionary is built as follows, using the functions described above.
text_filepath = 'microsoft2023.txt'
stopfile = 'englishST.txt'
text = load_words_as_string(text_filepath)
text = cleanup(text)
stop_words = load_words_from_file(stopfile)
stop_words = [cleanup(word) for word in stop_words]
word_counts = createWordCount(text,stop_words)
We're now in a position to build the word cloud.
Creating the Word Cloud
The cloud is created from the wordcloud.WordCloud class. There are many parameters that you can vary from the font and canvas dimensions, to the shape and color map used in the cloud (see the full documentation).
class wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2,
ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1,
color_func=None, max_words=200, min_font_size=4, stopwords=None,
random_state=None, background_color='black', max_font_size=None,
font_step=1, mode='RGB', relative_scaling='auto', regexp=None,
collocations=True, colormap=None, normalize_plurals=True,
contour_width=0, contour_color='black', repeat=False,
include_numbers=False, min_word_length=0,collocation_threshold=30)
We'll focus on adding a mask (defining a shape for the cloud), selecting a background color, and defining a colormap for the text.
Creating a Mask
The cloud can be masked to any shape that you wish by converting an image to a numpy array. When using a mask the width and height parameters are ignored and the shape of the mask is used instead, All white areas #FFFFFF or #FF are masked out while all other areas are free to be drawn on. We'll use this Microsoft logo as the basis for our mask. Download the mask file from Github to complete the tutorial.
You'll need to import numpy and PIL to build the mask, converting the png file to an array.
import numpy as np
from PIL import Image
mask_img = 'microsoft-mask.png'
mask = np.array(Image.open(mask_img))
Generate the Cloud
We now have everything we need to create the word cloud. We'll build the cloud and then attach it to a matplotlib figure using plt.imshow(). This gives you more control over the resulting image, and once a part of the matplotlib figure you can save it or display it as required.
Since we have built the dictionary word_counts as our input into the word cloud, we'll use the generate_from_frequencies(word_counts) method to build the cloud. If you are rather using plain text as the input then just call .generate(text) instead.
The height and width parameters are not required if using a mask as the canvas will be sized to the mask image.
Set the background color using the background_color parameter and a mask border color and weight from contour_color and contour_width as required.
Select a colormap from one of the predefined matplotlib colormaps or build your own.
The code required to generate and plot the word cloud is shown below. You can save the figure by calling plt.savefig(filename) rather than plt.show() if you want to save copy.
from wordcloud import WordCloud
wordcloud = WordCloud(colormap="winter", mask=mask,
background_color='black',contour_width=2,
contour_color='#00ff80').generate_from_frequencies(word_counts)
# Display the word cloud
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
The resulting word cloud looks pretty great. Not unsurprisingly the most popular word in the Microsoft keynote was also "AI", followed by "build" and "copilot".

This should give you a good start in order to generate your own word clouds. There is a lot more customization available, from changing the font to limiting the number of words to add to the cloud (the default is 200), or building a custom colormap to represent your brand. A big thanks again to the creators of the word_cloud package for building and open-sourcing this great tool!
If you want to try and build this yourself then download the text files and Jupyter Notebook from Github.
We'll Build It For You
Building professional looking word clouds can be time consuming and difficult to perfect if you don't have much experience using Python. This is especially true if you need a level of customization that includes custom cloud shapes (masks) and a specific set of colours, sizes, and fonts to match a particular brand.
Canard Analytics, has a full suite of word cloud tools that we can use to build you high-quality, custom word clouds on demand
Typically our clients not only ask for the cloud image, but also a tabulated summary of the most used words in the text, and also often the text transcription itself.
We've built a great word cloud reporting tool that outputs all of this and more in a document or image format.
Of course you no doubt have a very specific set of requirements that you need. Speak to us and let's see how we can help - not only with a word cloud, but with a full custom analytics solution to give your business the leg up that it needs to stay ahead of your competition. Our aim is to assist businesses to thrive in the digital economy and we'd love to work with you to make that happen.
